前回、故障したNAS(LS210D)の交換用HDDとして、SeagateのIronWolf「ST4000VN006」(4TB・CMR・NAS向け)を選んだところまで書いた。記事の最後はこう締めくくっていた──「次回は、購入したHDDを使ってNAS復活に挑戦です」と。
その「次回」が、ようやく書ける。
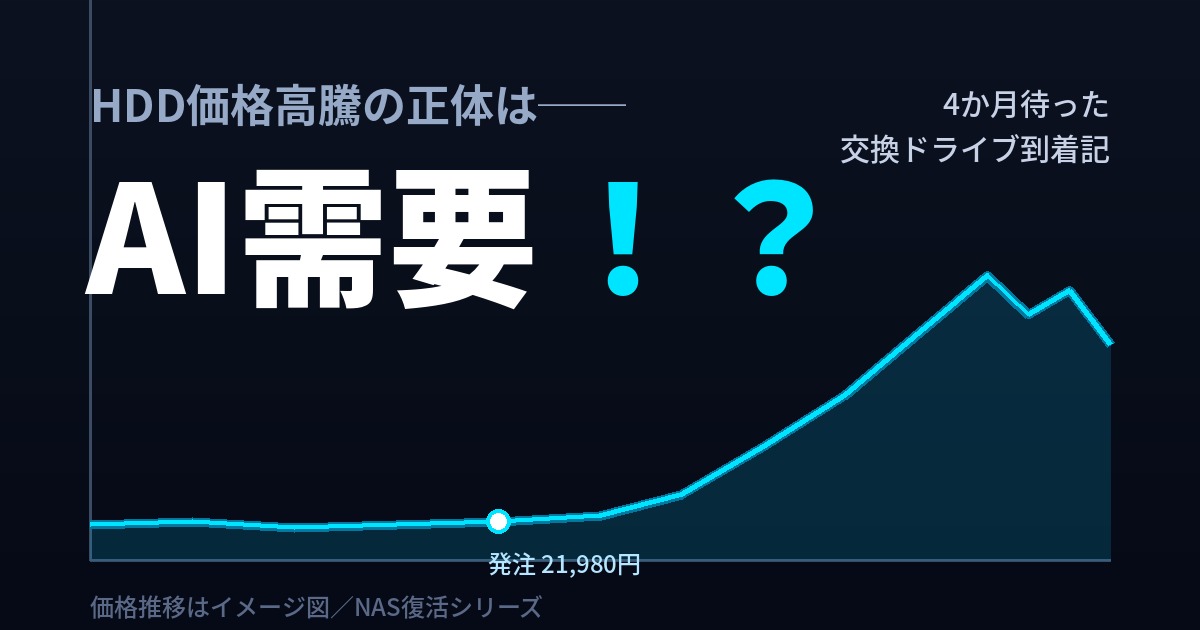
ただし、NAS本体の復活作業はもう一度先送りさせてほしい。理由は単純で、発注したHDDが届くまでに、4か月かかったからだ。 発注は2026年2月23日。到着は6月23日。きっかり4か月、入荷待ちが続いた。今回はまず、この「待たされた4か月」そのものを記録に残しておきたい。HDDという、ふだんは「ポチればすぐ届くもの」が、なぜこれほど待たされたのか。そして、2月に値段を確定して発注しておいた判断は、正解だったのか。
届いたもの ── 伝票とドライブ
まず、到着した実物から。

伝票の日付がそのまま記録になっている。発注 2026年2月23日 → 到着 2026年6月23日。 購入金額は21,980円(税込)。発注時点でこの価格は確定していた。

そして届いたST4000VN006本体。静電防止袋越しの一枚だが、ラベルの「Date(製造日)」を見て、思わず二度見した。表記は「06JUN2026」。製造日は2026年6月6日。 発注したのが2月、製造されたのが6月初旬、手元に届いたのが6月23日。つまりこのドライブは、私が注文してから3か月以上あとに作られた個体ということになる。倉庫で在庫が眠っていたのを待っていたのではなく、どうやら「作られるのを待っていた」可能性が高い。この点は後でもう一度触れる。
ちなみに、今回壊れて交換対象になった旧ドライブ(ST4000DM005)のラベルを見ると、製造日は「27APR2022」。2022年4月製だ。約4年動いて力尽きた個体を、2026年6月製の新品で置き換えることになる。
(余談だが、製造日「06JUN2026」=2026年6月6日というのは、少し気になる並びでもある。西洋では「666」が新約聖書『ヨハネの黙示録』に登場する「獣の数字」とされ、悪魔・反キリストを象徴する不吉な数として避けられてきた。6が三つ並ぶ6月6日は「恐怖の日」とも呼ばれ、映画『オーメン』などでも知られる。日本ではあまり馴染みのない忌み数だが、もしこのドライブを作ったタイの工場にキリスト教徒の従業員がいたら、出荷日のラベルを見て少し身構えたかもしれない──というのは、さすがに考えすぎだろう。データの保全に、語呂も縁起も関係ない。)
価格は、どう動いていたのか ── 価格.comの実データ
「待っている間に値段がどうなったか」を、体感ではなく実データで見ておきたい。価格.comのST4000VN006 価格推移グラフは、期間を1年・2年に切り替えると長期の推移も追える。これを踏まえて数字を並べると、いくつもの発見があった。
まず、長いスパンで見たときのベースの底上げ。
| 時点 | 価格.com価格 |
|---|---|
| 2022年8月(初値) | 14,979円 |
| 2026年2月23日(発注日・平均) | 25,253円 |
| 私の発注価格(2/23・確定) | 21,980円 |
このドライブの登録初値は14,979円。それが私の発注した2026年2月23日には平均25,253円まで上がっていた。2年半ほどで、ベースの価格が1.7倍近くになっている。 そして注目したいのは、私が確保した21,980円が、その2/23時点の平均25,253円よりも3,000円以上安かったこと。安い店を選んで発注した判断は、この時点ですでに効いていた。
次に、到着前後(5月下旬〜6月)の最安値の動き。
| 時期 | 価格.com最安値(税込) |
|---|---|
| 5月26日 | 37,308円 |
| 5月29日 | 38,090円 |
| 5月30日 | 27,980円(前日から約1万円下落) |
| 6月上旬 | 29,980円前後 |
| 6月13日 | 22,950円(一時的な下げ) |
| 6月14日 | 31,547円(翌日に約8,600円戻す) |
| 6月18日 | 32,980円 |
| 6月19日 | 25,500円(約7,500円下落) |
| 6月22〜24日(到着前後) | 24,980円 |
ここから二つのことが読み取れる。
ひとつは、私が2月に確保した21,980円という価格は、到着時の相場と比べても明確に安かったということ。到着した6月の最安値はおおむね2.5万〜3.3万円台で、5月下旬には3.8万円台に届いていた。発注時に値段を固定できたぶん、待っている間の値上がりを丸ごと回避できた格好だ。仮にいま同じものを買い直すなら、3,000〜1万6,000円ほど余計に払うことになる。
もうひとつは、価格が一日で7,000〜10,000円も上下していること。6月13日に22,950円まで下がったかと思えば、翌14日には31,547円へ跳ね上がる。これは需要が日替わりで動いているというより、「安値を出す店の在庫が出たり消えたりするたびに、最安ショップが入れ替わっている」動きに見える。薄い在庫を、複数の店が奪い合っている──そんな相場だ。
※価格は価格.comの掲載値(初値・平均・最安値)を参照。価格・在庫は常に変動するため、購入検討時は必ず最新の情報を確認してほしい。
なぜ高い ── 円安は「地ならし」、引き金は別にあった
HDDが高い、と聞くとまず「円安のせいだろう」と考えたくなる。輸入品である以上、円安が効いているのは間違いない。だが、価格.comの価格推移グラフを長期で眺めると、話はそう単純ではないことがわかる。価格推移グラフのページで表示期間を「1年」や「2年」に切り替えると、ここで述べる動きが自分の目で確認できるので、ぜひ実際のグラフと見比べてほしい。
長期グラフで決定的なのは、価格が動き出したタイミングだ。2025年7月から11月にかけて、最安値は17,000円前後でほぼ横ばい──むしろ秋口にはわずかに下げてさえいる。ところが2025年12月を境に、価格は急角度で上がり始める。 2026年に入って上昇は加速し、5月には平均45,000円超・最安値37,000円台のピークをつけ、6月にやや反落して現在に至る。
ここで為替を重ねてみる。円安はこの1年で急に始まったものではない。ドル円が150円を超える水準は2022年から続く長期トレンドで、2026年も年初に159円台をつけたあと、おおむね140〜160円のレンジで推移している。つまり、円安は2025年前半からずっと「効いていた」はずなのに、HDD価格が動き出したのは2025年末からだ。 もし円安が主因なら、価格は2025年前半から上がっていなければおかしい。だが実際には、横ばいの期間が半年以上続いたあと、為替とは無関係なタイミングで急騰が始まっている。
物価と為替は、しばしばずれて現れる。為替は輸入コストの「土台」を押し上げる地ならしではあっても、この急騰の引き金を引いたのは別の要因だ──そう考えるのが自然だろう。
ではその引き金は何か。報道で繰り返し指摘されているのは、生成AI向けのデータセンター需要である。HDDメーカーが利益率の高い大容量・データセンター向けの生産を優先し、結果として4TBクラスのような普及帯の供給が絞られた。Western Digitalは2026年生産分がほぼ完売で、上位クラウド事業者と2027〜2028年まで長期契約を結んでいると報じられている。日本経済新聞も、2026年4〜6月期のHDD大口取引価格が前四半期比で約1割上昇した背景として、中国のPC向け需要とデータセンター優先による品薄を挙げており、為替には触れていない。時期で見ても、AIデータセンター投資が過熱したのはまさに2025年後半から。価格が動き出した時期と、きれいに重なる。
ここで、冒頭の「製造日6月6日」が効いてくる。生産枠がデータセンター向けで埋まっている中では、一般向けの普及帯ドライブは「在庫から出てくる」のではなく「順番待ちで作られる」状況になりうる。私の個体が注文の3か月以上あとに製造されていたのは、まさにその順番待ちの結果だったのではないか──そう考えると、4か月の「入荷待ち」の正体に説明がつく。
この高値は、いつまで続くのか ── 二つの見方
では、この相場はいつまで続くのか。ここは断言を避けたい。見方が、はっきり二つに割れているからだ。
供給側から見れば、高止まりは当面続く。 メーカーの生産枠が2027〜2028年まで長期契約で埋まり、新しい生産ラインの立ち上げには年単位の時間がかかる。だから多くの分析は「2026年中に以前の安値へ戻ることは期待しにくく、緩和は早くて2027年以降」で一致している。この見方に立てば、いま高くても待つ意味は薄い。
だが需要側を見ると、雲行きが変わりつつある。 価格急騰を支えてきたAIデータセンター需要そのものに、調整の兆しが出始めているのだ。2026年に米国で完成予定だったデータセンターの約半数が遅延・中止に追い込まれ、マイクロソフトは計画容量の一部を延期したと報じられている。地域住民の反対運動も激化し、2026年1〜3月だけで総額20兆円規模のプロジェクトが停止・延期、ニューヨーク州議会は新規大規模データセンターの建設を一時停止する法案を可決した。AIの収益化が想定より遅れ、企業間の「勝ち負け」が見え始めているという指摘もある。
もし、過剰投資の調整が本格化し、撤退する企業の発注分が宙に浮けば、データセンター向けのHDD需要は想定より早く緩む可能性がある。そうなれば、普及帯に回ってくる供給も増え、価格が落ち着く展開もあり得る。「2027年まで高止まり」は供給側の論理であって、需要側が崩れれば前提ごと変わる。 どちらに転ぶかは、正直なところ読みきれない。
確実に言えるのは、この相場は「構造的に高い」のではなく、「AI需要という一本の柱に支えられて高い」ということだ。柱が太いままなら高値は続くし、柱が細れば崩れる。HDDの値段を、為替やインフレといった大きな話だけでなく、AI産業の浮き沈みという生々しい現実と結びつけて眺めておくと、買い時の判断材料になるかもしれない。
「他店ではすぐ買えた」という事実 ── 入荷待ちは店の問題でもある
ここは正直に書いておきたい。私が4か月待っている間も、もっと高い値段を出している他店では、在庫があってすぐ買えた。 価格.comでも、2月から6月を通じて在庫表示「△」ながら複数のショップが販売を続けていた。
つまり、市場全体でST4000VN006が完全に払底していたわけではない。「すぐ届く店は高く、安い店は入荷待ち」という、ごく当たり前の構図がそこにあっただけだ。私は安い店を選び、そのぶん時間を払った。供給が絞られた相場では、低価格で出てくるのは余剰のぶんだけで、それを安値で確保しようとすれば順番を待つことになる。価格と納期は、たいてい交換条件になる。
「すぐ欲しい」か「待てる」かで、買い方は変わる
この4か月で得た教訓を一つに絞るなら、HDDの買い方は「すぐ欲しいか/待てるか」で根本的に変わる、ということだ。
今回の私のNASは、前回書いたとおり、NAS全体で多重化しており、お金を払ってまで急いで復旧すべきデータはなかった。だから「待てる」側だった。納期を犠牲にして安い店を選び、結果として高騰相場の値上がりも乱高下も回避できた。これは「待てる」人にとっての最適解だったと思う。
逆に、いま現に運用中のストレージが壊れて、バックアップの空白を一日でも早く埋めたい──そういう「すぐ欲しい」状況なら、話はまったく違う。最安値を狙って入荷待ちに賭けるより、多少高くても即納の在庫を押さえるほうが、トータルでは正しい。相場が高止まりし、しかも日替わりで乱高下する局面では、「最安のタイミングを当てにいく」こと自体がリスクになる。先に見たとおり、この先の相場は供給側・需要側のどちらに転ぶか読みきれない。だからこそ「いつか下がるはず」と当てにして運用に穴を空けるより、自分の状況が「待てる」のか「待てない」のかを先に見極めるほうが、よほど確実だ。
ひとつ補足すると、HDD選びでは「すぐ欲しい/待てる」だけでなく、SMRかCMRか、容量単価はどうか、といった軸も絡んでくる。このあたりは前回で詳しく検討したので、そちらも参照してほしい。
余談:このドライブは「どこ製」なのか
最後に、ラベルを眺めていて気になった点を一つ。製造国の表記についてだ。
今回届いた個体のラベルには「Product of Thailand」とあった。タイで組み立てられたドライブ、というわけだ。面白いことに、今回壊れた交換前のドライブ(ST4000DM005)も、同じく「Product of Thailand」だった。製造日は4年違い、型番も製品系列も違うのに、組み立て地は同じタイ。Seagateにとってタイが主力の組み立て拠点であることがうかがえる。
ただ、この「Product of Thailand」を見て「このドライブはタイ製だ」と言い切るのは、実はかなり乱暴な話だ。ラベルが示しているのは、あくまで最終的な組み立て(アッセンブリ)を行った国にすぎない。
HDDは、プラッタ(ディスク)、磁気ヘッド、スピンドルモーター、サスペンション、制御基板、ファームウェア──と、無数の精密部品の集合体だ。そして、これらの中核部品を誰が作っているかは、公開されている事実である。たとえば磁気ヘッドはTDKが専業の世界トップメーカーで、記録媒体であるプラッタはレゾナック(旧昭和電工)やガラス基板のHOYA、プラッタを回すスピンドルモーターはニデック(日本電産)やミネベアミツミ、磁気ヘッドを支えるサスペンションはニッパツ(日本発条)やTDK──というように、部品ごとに供給メーカーがはっきり分かれており、その多くは日本企業だ。 Seagateのような完成品メーカーはヘッドやメディアを内製もするが、それでも供給安定のために外部からも調達するのが普通である。
だから「○○製だから良い/悪い」という見方は、HDDに関してはほとんど意味をなさない。ラベルの「Product of Thailand」は「タイで組まれた」ことを示すだけで、中身の部品は世界中──とりわけ日本──のメーカーから集められている。組み立て地はラベルで分かっても、中身がどこの何でできているかまでは、ラベルからは読み取れない。これはこのドライブに限った話ではなく、HDDという製品そのものの素性なのだ。
次回こそ ── 届いたHDDでNAS復活へ
というわけで、交換用ドライブはようやく手元に揃った。4か月分の「待ち」も含めて、いい記録になったと思う。
次回は、いよいよこのST4000VN006を使って、故障したLS210Dの復活に挑戦する。分解したNASに新しいドライブを組み込んで、はたして無事に動き出すのか。あるいは、HDD交換だけでは済まない別の問題が待っているのか。実作業の記録は、次回に。





 深刻
深刻